香港科技大学和字节跳动Seed团队联合提出了WMPO(世界模型驱动的策略优化框架),通过像素级视频生成世界模型实现VLA(视觉-语言-动作)模型的无真实环境交互on-policy强化学习,显著提升样本效率、任务性能、泛化能力与终身学习能力,同时涌现出自修正等高级行为。本文已经被ICLR2026接收。
- 论文标题:WMPO: World Model-based Policy Optimization for Vision-Language-Action Models
- 论文链接:https://arxiv.org/pdf/2511.09515
- 项目主页:https://wm-po.github.io/
研究背景与核心痛点
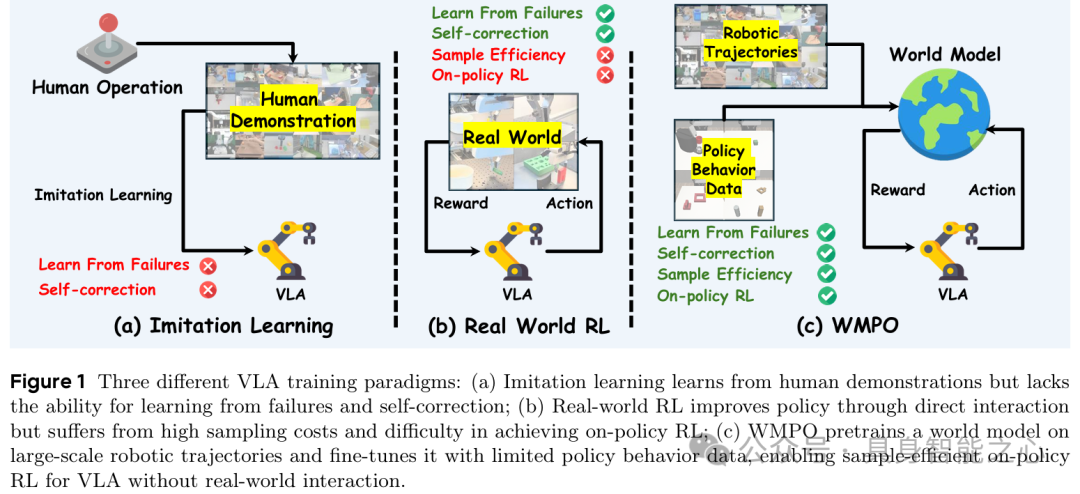
- VLA模型是通用机器人操作的关键范式,但主流模仿学习范式存在固有缺陷:面对训练中未见过的分布外状态时易出错,且无法从失败中学习和自修正(figure 1a)。
- 强化学习虽能通过环境交互实现自改进,但直接应用于真实机器人时样本效率极低,需数百万次交互,既不切实际也存在安全风险(figure 1b)。
现有解决方案难以兼顾规模化与有效性:人类干预引导学习需持续监督,难以扩展;仿真器适配多样场景成本高;传统 latent 空间世界模型与VLA的web-scale预训练视觉特征存在天然错位,无法充分利用预训练知识。
核心框架:WMPO 整体设计
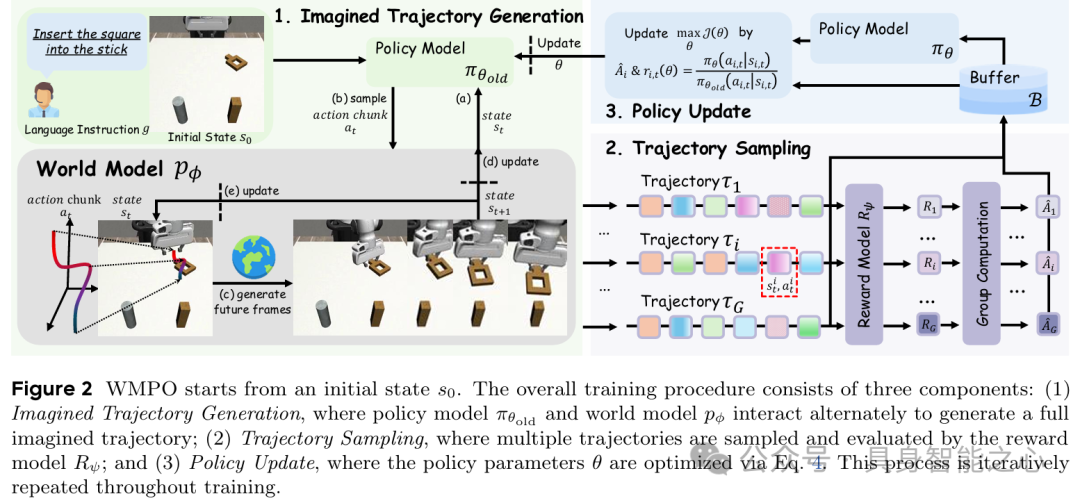
WMPO的核心逻辑是将VLA策略优化完全置于“想象”空间——基于高保真像素级世界模型生成轨迹,替代真实环境交互,同时支持更强的on-policy强化学习。整体流程遵循“想象轨迹生成→轨迹采样评估→策略更新”的迭代循环(figure 2)。
关键模块详解
生成式世界模型
核心作用是仿真机器人与环境的动态变化,生成与VLA预训练特征对齐的视觉轨迹,为策略优化提供可靠“虚拟训练场”。
- 结构设计:基于OpenSora的视频扩散backbone,将3D VAE替换为SDXL的2D VAE,更好保留细粒度运动细节,避免时间维度失真;扩散过程在VAE latent空间进行,优化时解码回像素空间以匹配VLA预训练习惯。
- 轨迹生成逻辑:给定初始c帧图像和语言指令,策略预测长度为K的动作块,世界模型基于前c帧和动作块生成下K帧;重复该过程直至生成完整轨迹(长度N)。
- 关键优化手段:
- 策略行为对齐:先在Open X-Embodiment大规模机器人轨迹数据集预训练,再用策略自身收集的真实轨迹微调,弥补专家演示中失败场景的缺失,让模型能精准仿真成功与失败模式。
- 长horizon生成保障:引入噪声帧条件(训练时对条件帧添加扩散噪声)提升鲁棒性,采用帧级动作控制(通过扩展AdaLN块注入动作信号和扩散时间步嵌入)解决动作-帧错位问题,实现数百帧无质量损失的轨迹生成。
轻量级奖励模型
核心作用是自动判断想象轨迹的任务成败,提供稀疏奖励信号,避免复杂奖励塑造和奖励攻击。
- 训练方式:以VideoMAE为编码器,搭配线性输出头,采用二分类交叉熵损失训练;正样本为成功轨迹的终端片段,负样本来自成功轨迹的非终端片段和失败轨迹的任意片段,训练时平衡正负样本比例。
- 推理逻辑:用滑动窗口遍历轨迹,计算每个片段的成功概率,若任一片段概率超过阈值,则判定整个轨迹成功。
On-Policy 策略优化(GRPO)
选择Group Relative Policy Optimization作为优化算法,适配稀疏奖励场景,兼顾稳定性与扩展性。
- 动态采样策略:从真实环境初始状态出发,生成G条想象轨迹,过滤掉全成功或全失败的轨迹组,避免梯度消失,确保训练样本的有效性。
- 优化目标:其中 为新旧策略的概率比, 为轨迹的归一化优势值。
- 无KL正则化设计:减少内存消耗,同时鼓励策略探索新颖且有效的行为。
核心创新点
- 像素空间优先:摒弃传统 latent 空间世界模型,直接在像素空间生成轨迹,完美匹配VLA的预训练视觉特征,充分释放预训练知识的价值。
- 策略行为对齐:通过策略自身轨迹微调世界模型,解决专家演示与策略实际行为的分布错位问题,让“想象”更贴近真实执行。
- 长轨迹生成技术:噪声帧条件+帧级动作控制,突破长horizon视频生成的视觉失真和动作错位瓶颈。
- 无真实交互的on-policy RL:依托世界模型实现大规模轨迹采样,既规避真实环境的高成本,又享受on-policy方法的性能优势,超越主流off-policy方案。
实验验证与关键结果
仿真环境性能(Mimicgen平台)
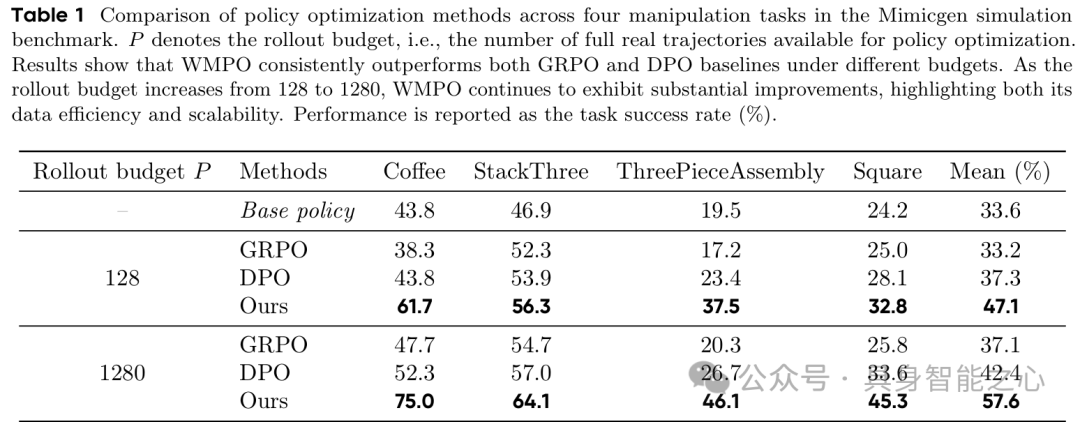
- 对比GRPO、DPO等基线方法,WMPO在4个精细操作任务(Coffee_D0、StackThree_D0等)中均表现最优(table 1)。
- 样本效率突出:rollout预算仅128时,平均成功率47.1%,超最强基线9.8个百分点;预算提升至1280时,平均成功率达57.6%,优势扩大至15.2个百分点,证明其能高效利用额外数据。
真实环境验证(Cobot Mobile ALOHA平台)
在“方块插入杆子”任务(间隙仅5mm)中,WMPO成功率70%,显著高于基础策略(53%)和DPO(60%);世界模型能精准预测真实轨迹的演化,即使未见过该轨迹也能捕捉核心动态(figure 7)。
涌现行为
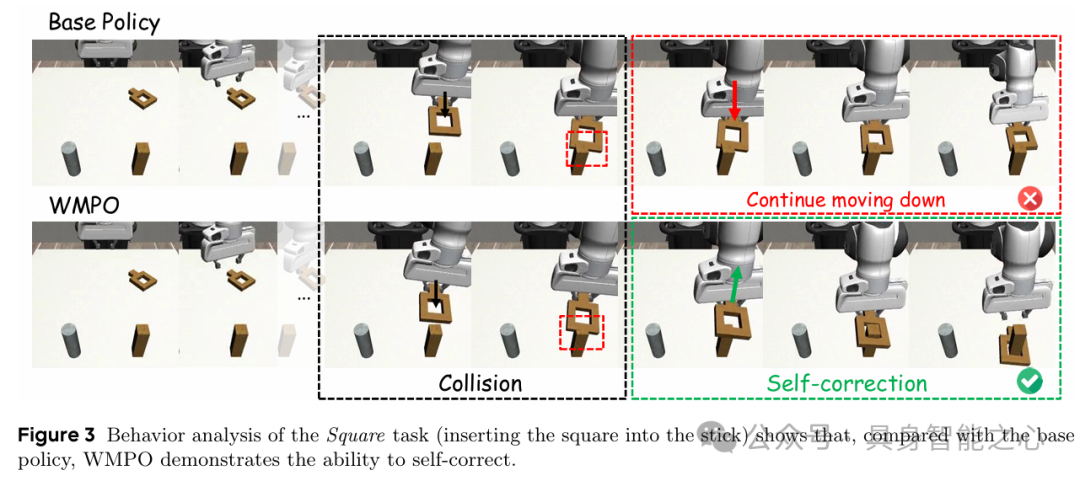
- 自修正能力:面对碰撞等失败状态,能自主调整动作(如抬起方块重新对齐),而基线策略会持续错误动作直至超时(figure 3)。
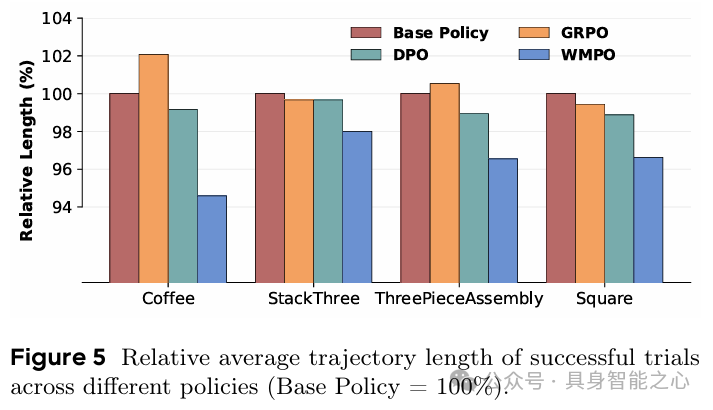
- 高效执行:成功轨迹长度显著短于基线,避免“卡壳”现象,动作更流畅(figure 5)。
泛化能力
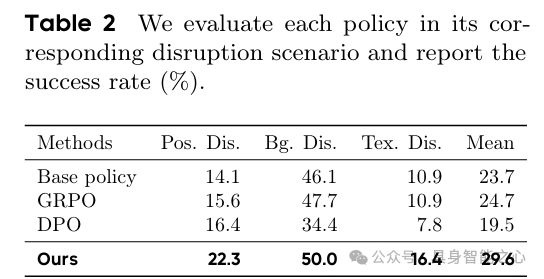
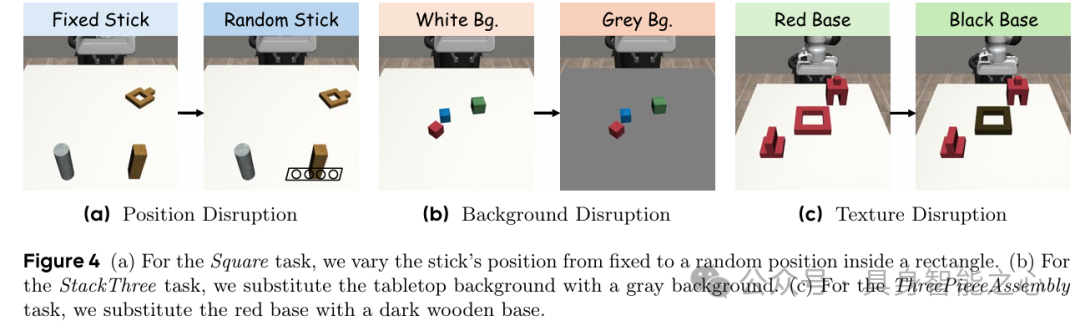
在空间扰动(杆子随机位置)、背景替换、纹理替换三种分布外场景中,WMPO平均成功率29.6%,优于所有基线(最高24.7%),证明其学习的是通用操作技能而非虚假视觉线索(table 2、figure 4)。
终身学习
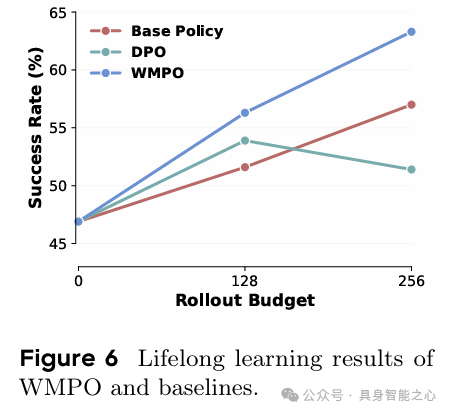
迭代收集128条轨迹进行优化,性能持续稳定提升;而DPO训练不稳定,无法实现迭代改进,且WMPO无需人类标注,比依赖更多专家演示的基线更具扩展性(figure 6)。
结论与意义
WMPO构建了“世界模型+on-policy RL”的VLA优化新范式,核心价值在于解决了真实环境交互成本高、样本效率低的行业痛点。通过像素级世界模型与VLA预训练特征的精准对齐,以及创新的长轨迹生成和策略优化设计,实现了性能、泛化性、终身学习能力的全面提升,同时涌现出自修正等高级行为,为通用机器人操作的规模化落地提供了可行路径。未来可扩展至流基策略,适配更多动作空间类型。
文章作者朱方琪受邀参加具身智能之心分享会,链接如下:
哔哩哔哩:
第一节:https://www.bilibili.com/video/BV13qkKB6EcM/?spm_id_from=333.1387.homepage.video_card.click
第二节:https://www.bilibili.com/video/BV1rZr1BvEaC/?spm_id_from=333.1387.homepage.video_card.click
文章转载自:具身智能之心
原文链接:https://mp.weixin.qq.com/s/oKJqK9VxAlUzjIoKlPO8tQ

.png)
