Updated on
August 12, 2025
港科大联合上海AILAB、浙江大学、华为提出变量自适应扩展的MoE气象预测模型。

自2022年以来,国内外顶级研究机构陆续发表了多款AI气象大模型,如华为Pangu-Weather,谷歌的GraphCast, 上海人工智能实验室的风乌系列气象模型等。但已有的大模型的提供的天气预测变量通常是确定的(如不同气压层的风温湿压及常规的地表要素),然而在一些垂直行业的应用中,通常需要更多的气象变量,如航空气象中要求提供100米及200米高度的风速预测。对于已有的大模型而言,增加变量意味着需从头开始训练一个模型,需要大量的计算成本和训练时间。为了在扩展变量时无须从预训练重新开始,这篇文章提出增量天气预报思想,允许AI气象预报模型的持续扩展,并提出了一种新颖的网络结构来实现变量的灵活扩展。具体而言,该研究提出了一种通道适应的专家模型(Variable Adaptive-Mixture Of Expert, VA-MOE),通过分而治之的策略将不同的变量通过索引嵌入分配给不同的专家进行训练,并在专家融合时通过通道级的Top-K策略降低计算复杂性。在ERA5数据集上进行的实验表明,改方法在增量阶段仅使用约15%的可训练参数,便可使得增加的变量达到了与先进AI模型相当的性能。
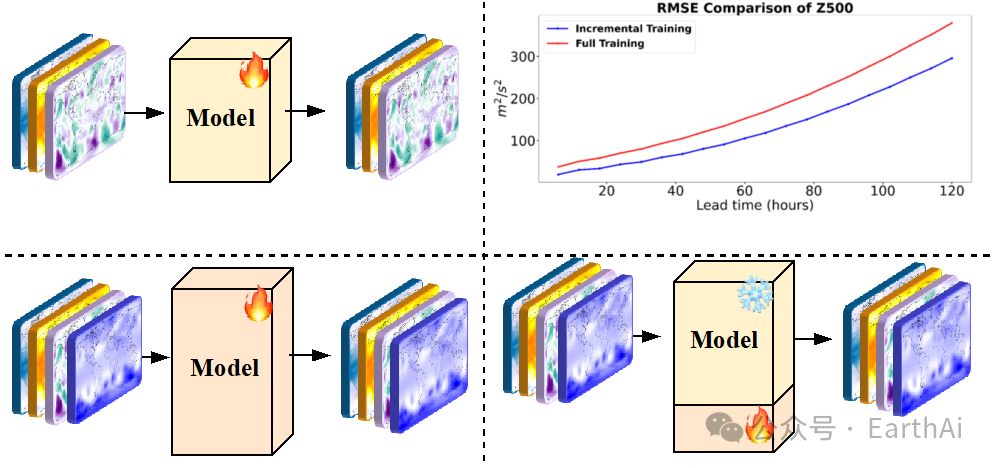
研究动机源于气象业务对实时数据融合与可持续扩展的迫切需求。随着卫星、探空仪等观测技术的进步,气象变量数量和类型持续增长,但传统方法每次新增变量都需全模型重新训练,严重制约业务时效性。VA-MoE的创新范式将气象预测重构为增量学习问题,通过两阶段训练(初始阶段优化基础变量→增量阶段整合新变量)实现"参数高效扩展"。其核心价值在于:1)首次系统性研究气象预测的增量学习基准;2)通过变量索引嵌入实现专家动态激活,其中,CAE模块能选择性处理新增地表变量(如U10、T2M)而不干扰高空变量(如Z500)的预测;3)为地球系统建模提供可扩展框架,推动AI4Weather领域从静态预测向动态适应演进。
研究的科学问题在于设计动态适应的专家选择机制与损失函数优化。现有MoE模型采用均匀权重分配,导致专家输出同质化,难以捕捉大气变量的层次化特征(如温度瞬变与位势高度的慢变差异)。为此,作者提出变量自适应门控机制,通过变量索引嵌入(Variable Index Embedding)引导专家专业化分工,但需解决两个关键问题:一是如何在不引入辅助损失的情况下,通过位置元数据编码实现专家领域特异性;二是如何设计梯度缩放的自适应损失函数,使优化速率与变量时空特性匹配。如图1所示,增量训练阶段需冻结预训练专家参数,仅训练新增变量对应模块,这对模型架构的灵活性和稳定性提出了极高要求。实验证明,这种设计需精确平衡计算开销与预测性能,例如在ERA5数据集上仅用25%可训练参数和50%初始数据达到SOTA效果。

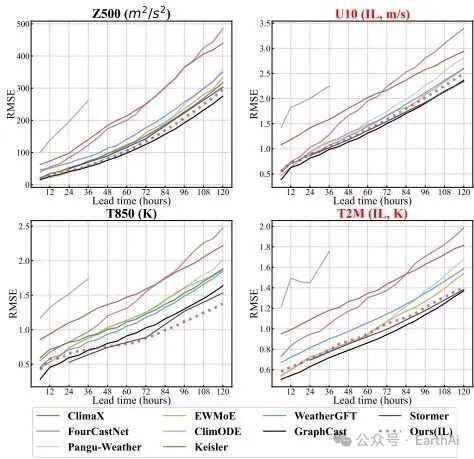
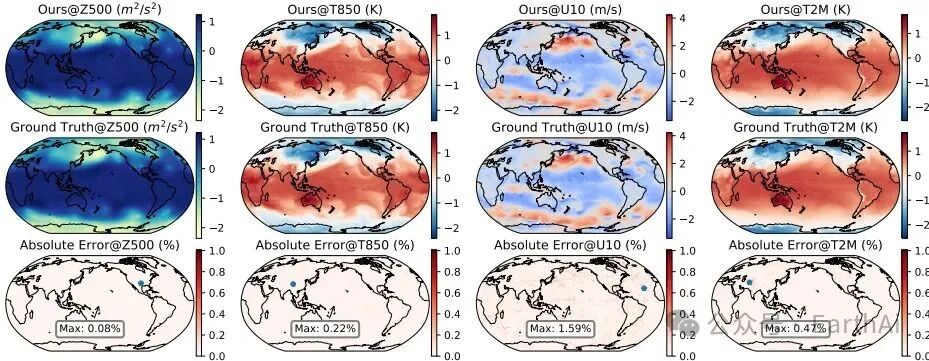
这篇论文提出了Variables-Adaptive Mixture of Experts (VA-MoE),用于解决增量天气预测中的时空模式动态适应问题。具体来说,VA-MoE通过以下方法实现:
转载自:EarthAi
原文地址:http://mp.weixin.qq.com/s/LHKnCZjb52M8hPyPqfw2AQ
.png)
