.png)
What I cannot create, I do not understand. --Richard Feynman
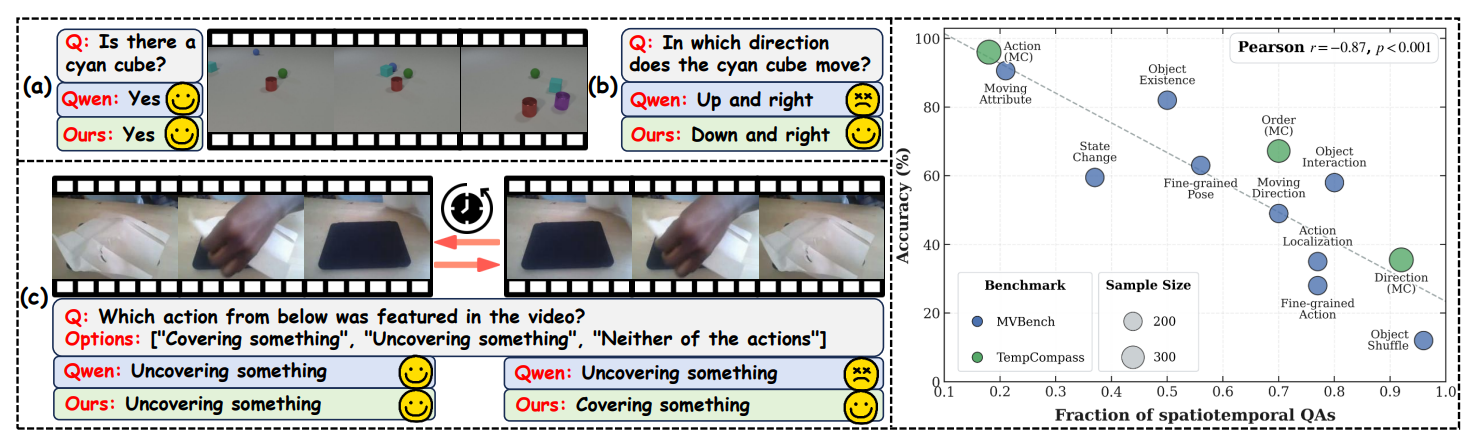
A video reasoning model can look accurate on benchmarks yet still rely on static shortcuts. The real test is spatiotemporal sensitivity: if motion direction, temporal order, or event dynamics change, the answer should change for the right reason.
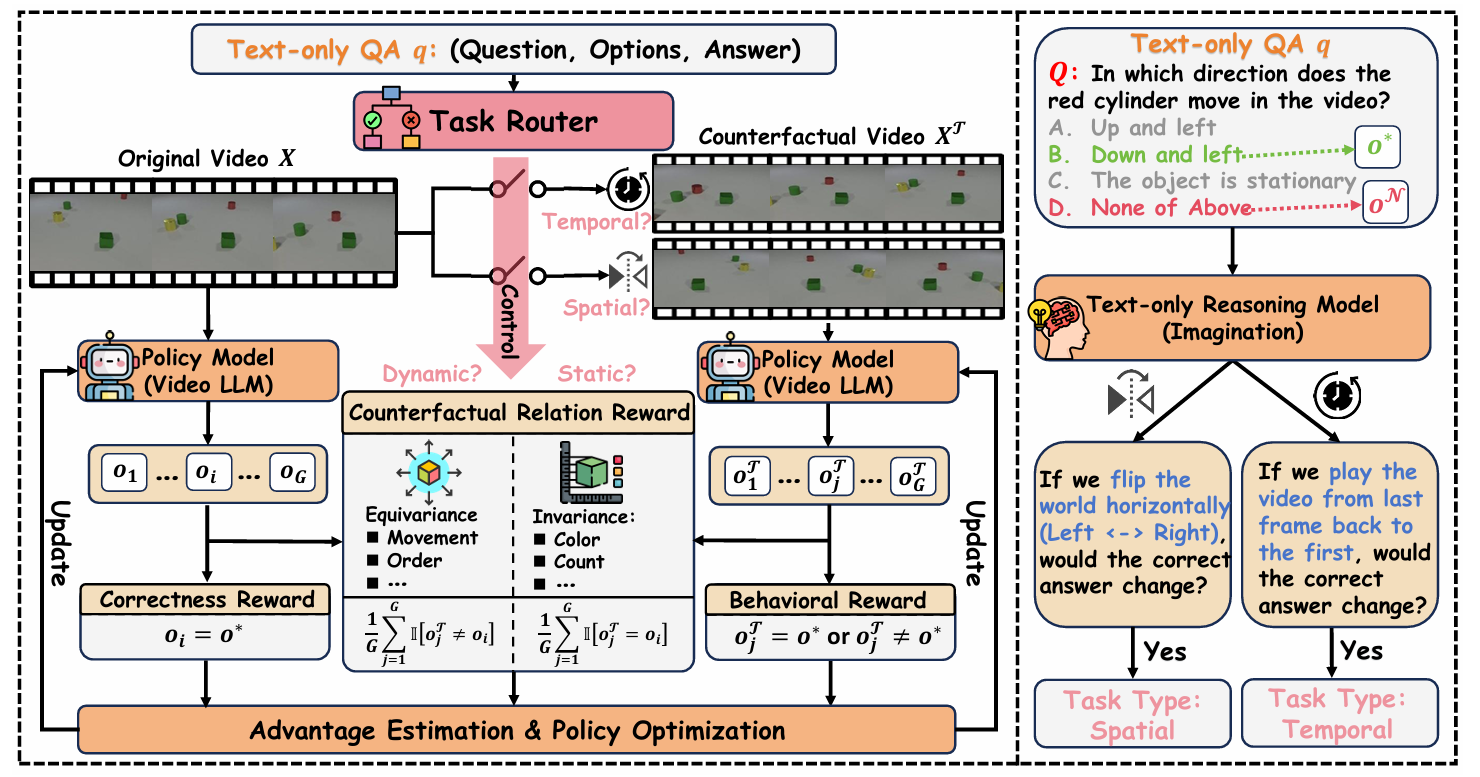
Our method follows a counterfactual RL view: we train on paired original / transformed videos and enforce cross-branch relational consistency with CRR. This makes shortcut policies much harder to optimize and pushes the model toward motion-grounded reasoning.
Why it matters:
More details can be found at: https://ddz16.github.io/crpo.github.io/
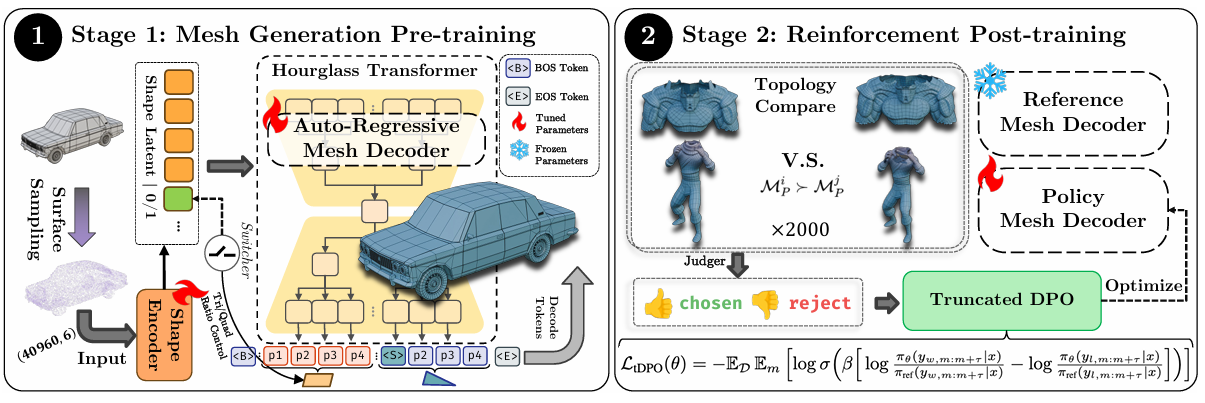
In production 3D workflows, quality is not only about geometry fidelity, but also about editability, deformation stability, and artist-friendly edge flow. Direct native quad generation matters.
Our method predicts mixed triangle/quad face sequences directly with an autoregressive model, then refines topology quality via tDPO preference optimization rather than fragile post-hoc conversion.
What this unlocks:
More details can be found at: https://hitcslj.github.io/QuadGPT/
See QuadGPT below:
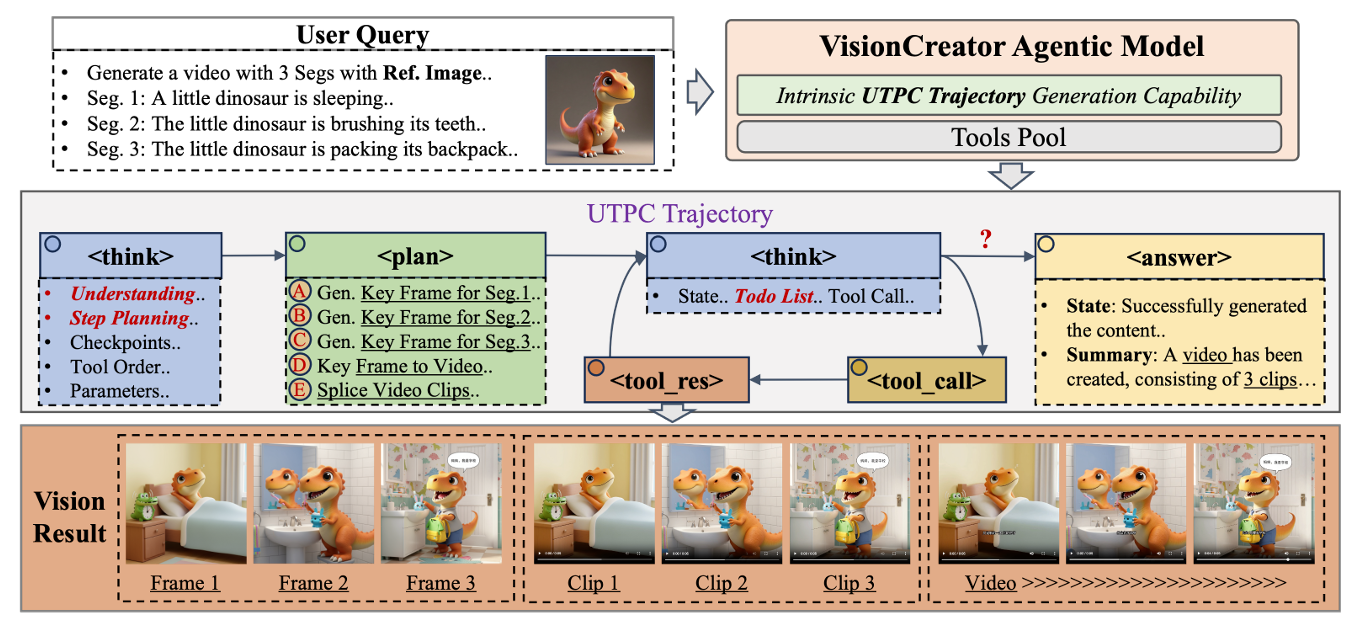
High-quality visual creation is not one-shot generation. It needs a system that can understand intent, reason over constraints, plan multi-step actions, and execute reliably.
Our method treats this as a native UTPC loop (Understanding–Thinking–Planning–Creation), then scales capability with PST and VRL in simulated environments for long-horizon tasks.
Why our method matters:
More details can be found at: https://layjins.github.io/visioncreator/
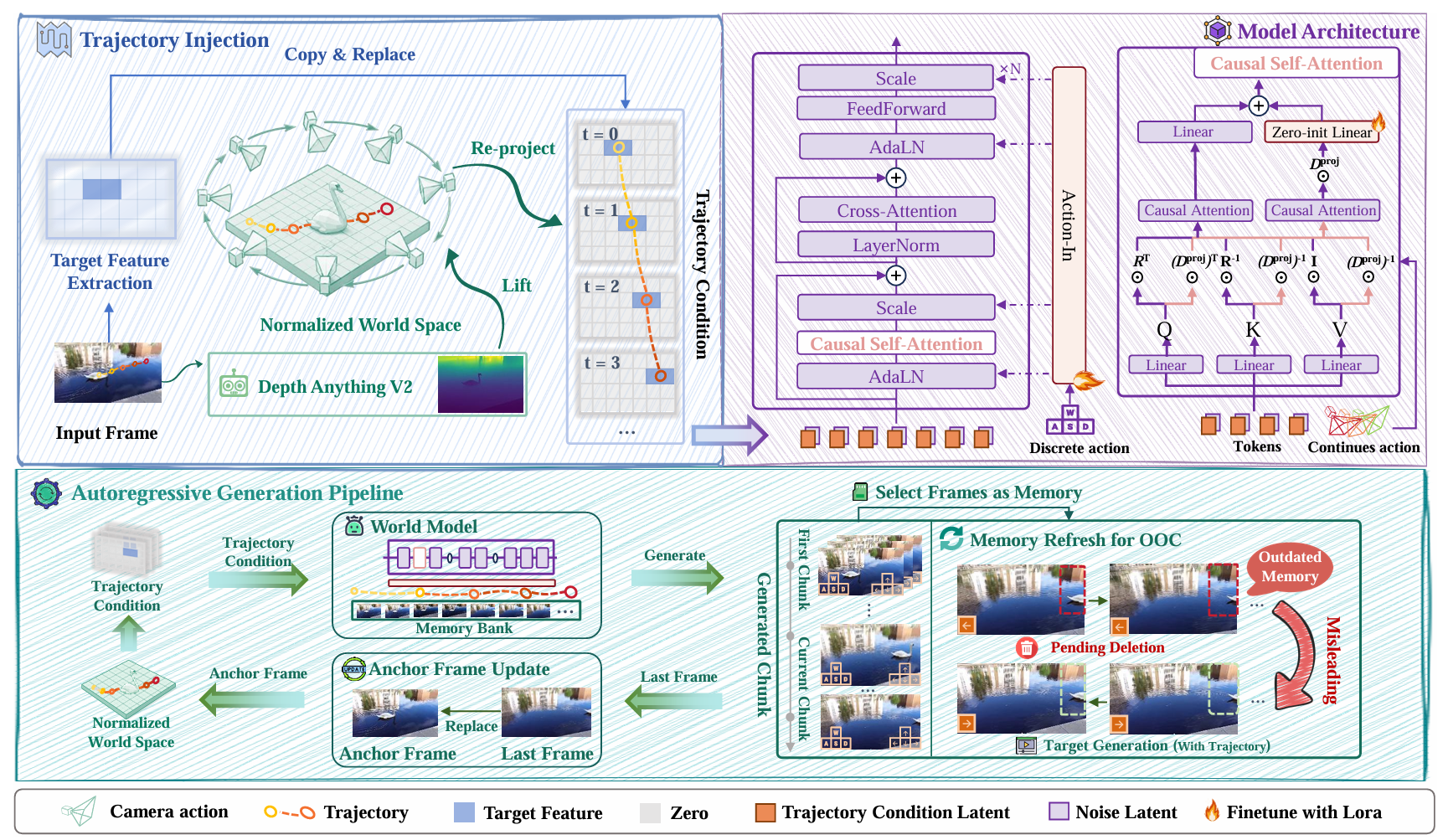
Camera navigation alone is not enough for a truly interactive world model. Real interaction is object-centric: click an object, sketch a path, and generate coherent future frames under moving viewpoints.
Our method decomposes this into three key pieces: camera-invariant trajectory representation, non-destructive control injection, and persistent state memory for long autoregressive rollouts.
Why it matters:
You can find WorldCraft at: https://nevsnev.github.io/WorldCraft/
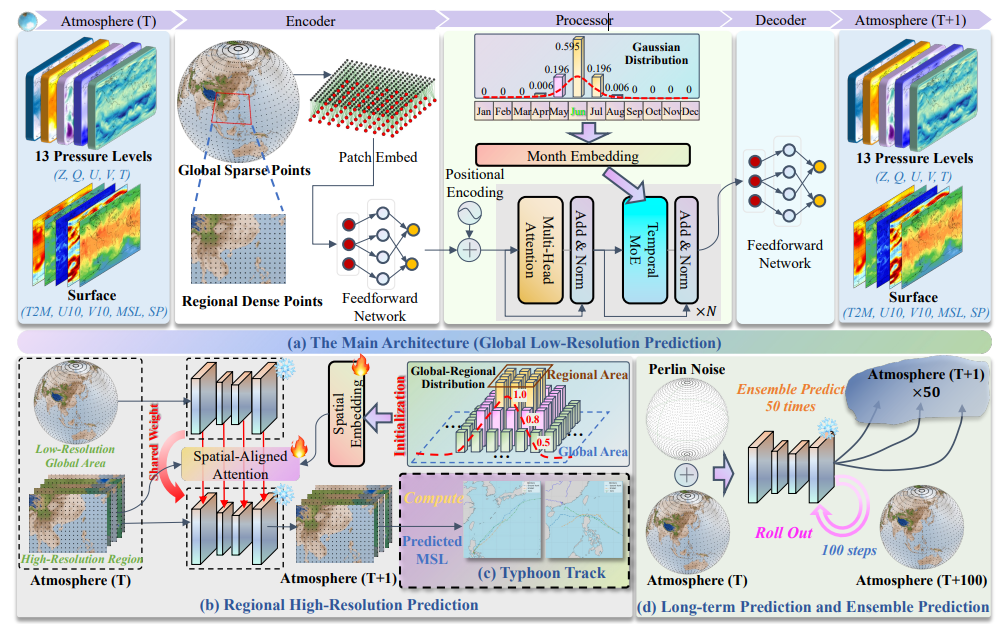
High-resolution regional weather forecasting is hard to scale if we ignore Earth-wide dependencies. Neighbor-only boundary assumptions often miss long-range interactions, while direct high-resolution global modeling is computationally prohibitive.
Our method, STCast, addresses this with two coordinated components: SAA (Spatial-Aligned Attention) for adaptive global-regional boundary coupling, and TMoE (Temporal Mixture-of-Experts) for month-aware temporal specialization. Together, they form a unified framework evaluated on global forecasting, regional forecasting, extreme event prediction, and ensemble forecasting.
Why it matters:
You can find STCast at: https://github.com/chenhao-zju/STCast
More about PEI-Lab climate analysis advances are hilighted by:
https://www.linkedin.com/feed/update/urn:li:activity:7462197494102372352/
