.png)
Systems that scale with intelligence.
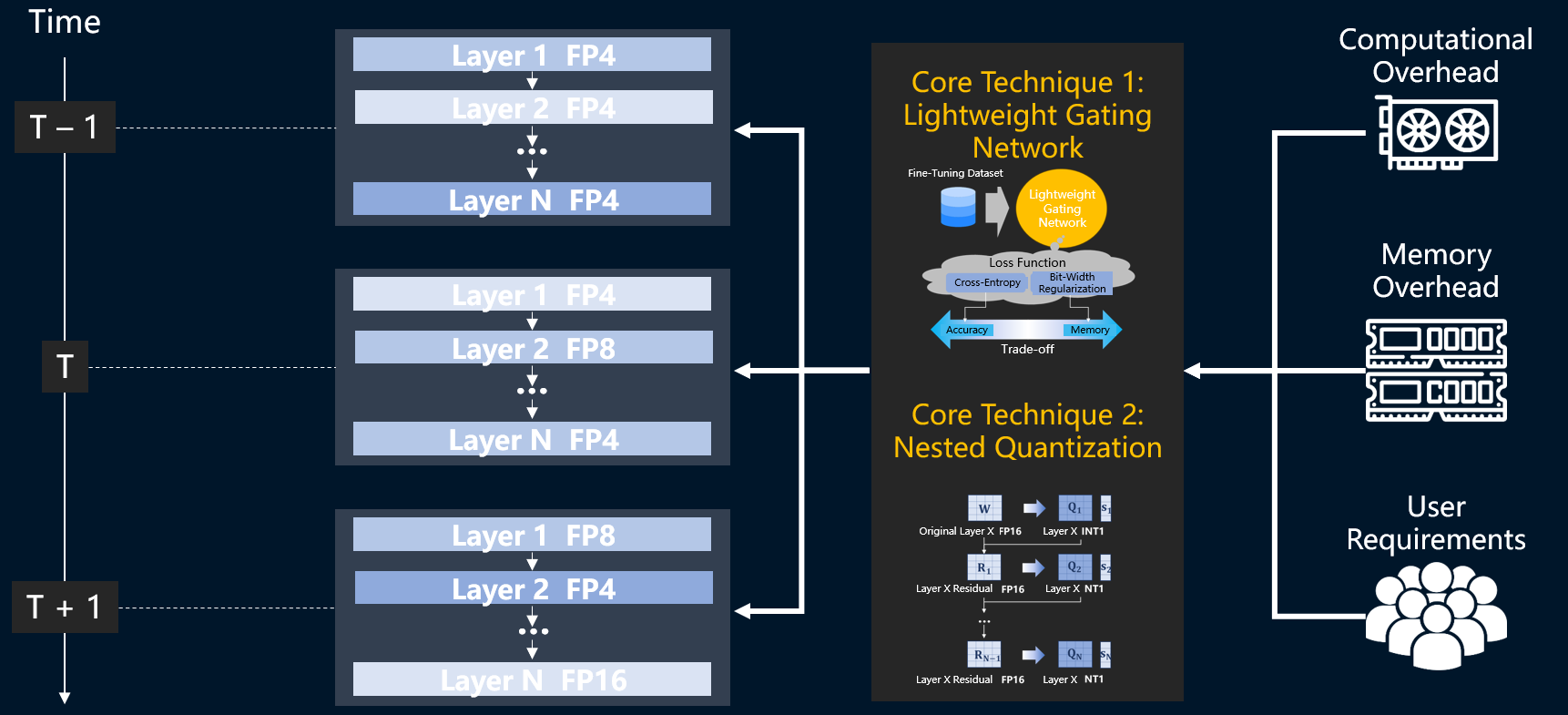
Mixture-of-Experts (MoE) models keepcompute cheap by firing only a few experts per token — but every expert stillhas to be in memory, and Mixtral 8×7B wants tens of GB. Uniform quantization istoo blunt: some experts barely tolerate INT4, some tokens deserve INT8, and onedge devices the real wall is streaming experts from storage.
D²MoE is analgorithm–system co-design that mixes precision per-token, per-layer, on thefly:
Up to 3.37× higher throughput onJetson Orin under tight memory budgets, with INT8-level accuracy and noretraining required.
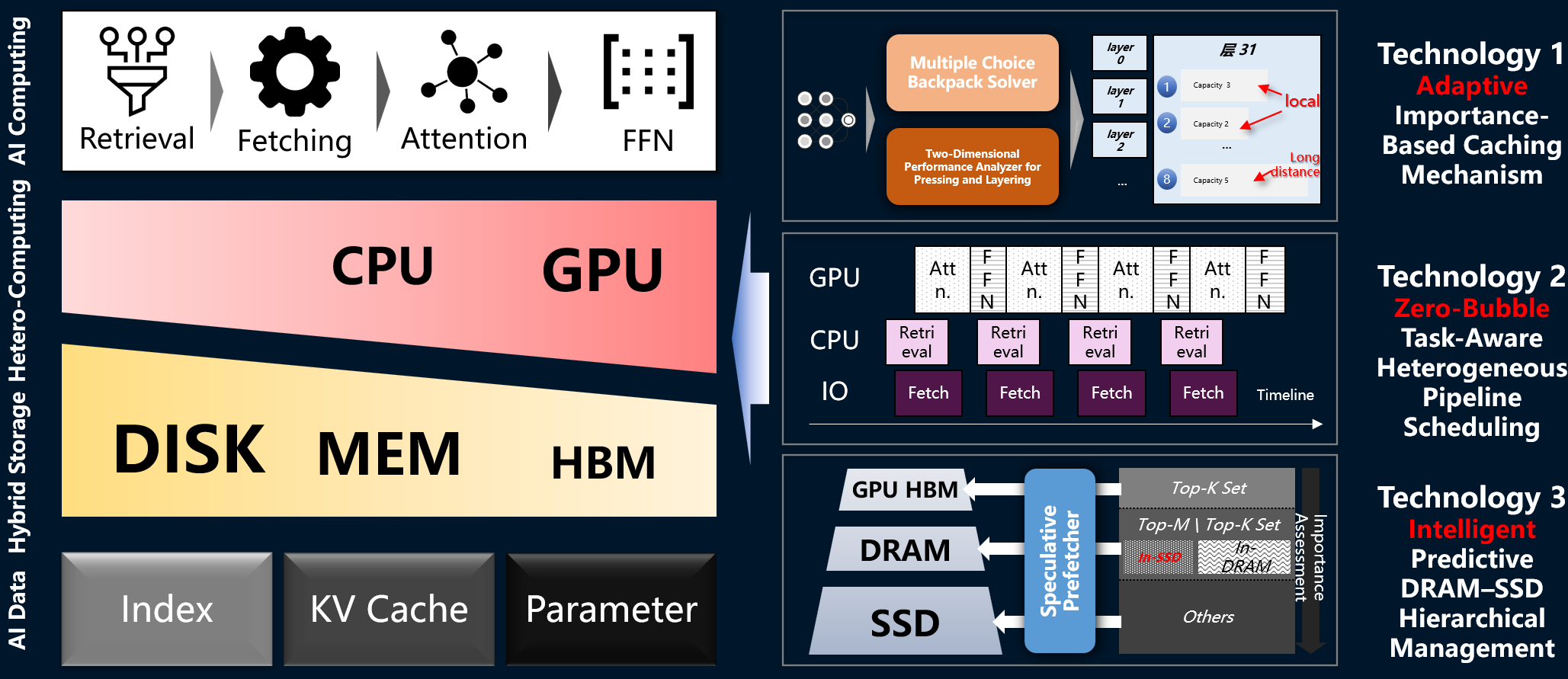
A 100K-token context on Llama-3-8B withbatch 8 needs ~100 GB just for the KV cache — far more than any commodity GPU.Offloading to host DRAM helps, but sparsity has a ceiling, and once contextsgrow, the transfers themselves become the bottleneck. Half of decodingtime is spent waiting for KV entries.
KVDriverethinks the problem across GPU HBM, host DRAM, and SSD as one coordinatedhierarchy:
Up to 1.74× throughput over the best KV-offloading baselines, with accuracy preserved. A24 GB RTX 4090 running KVDrive can outperform a 96 GB H20 on standard servingby up to 3× — long context moves from datacenter to workstation.
See KVDrive below 👇

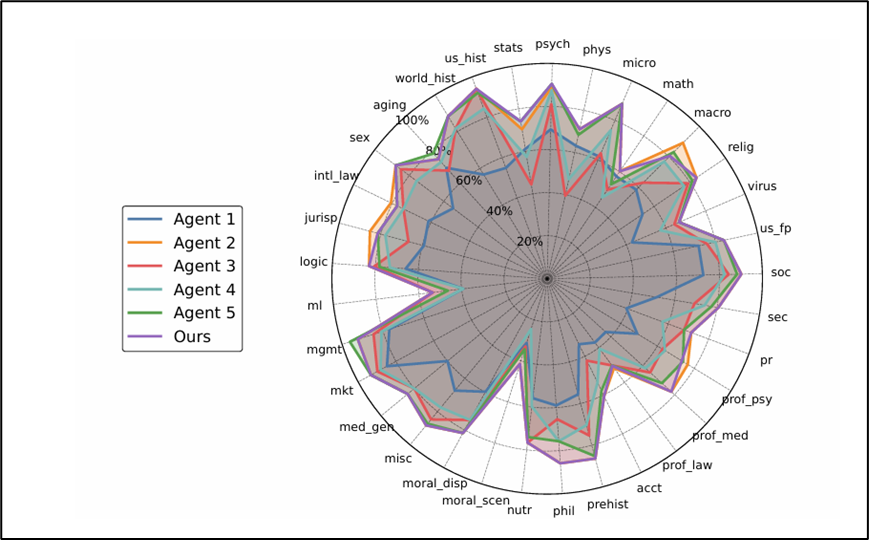
Every device is becoming an AI device, andpeople are starting to do with on-device LLMs what they once did with files:customize them. One agent gets sharp at law, another at medicine, another atcode — and weaker at everything else. The BitTorrent question, twenty yearslater: when your local agent isn't the right one, why not borrow a peer's?
The catch is that agents aren't files. Thepool churns; capabilities overlap; and the best agent for a query isalso the most asked-for, so naive routing creates hotspots. PPAI handlesboth:
+7.96% accuracy over centralized routing baselines, −16.34% latency under heavy demand. Andit scales the right way: going from 50 to 1000 agents lowers latency ratherthan raising it.
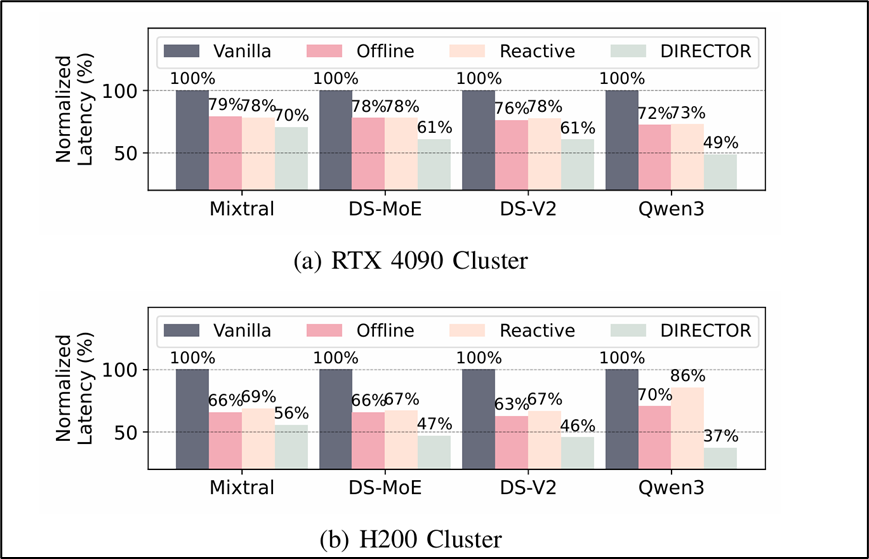
When MoE models get big enough to need awhole cluster — Mixtral, DeepSeek, Qwen3 — the experts get spread across GPUs,and every token has to find its way to the right ones via all-to-allcommunication. Which experts sit on which GPU turns out to mattera lot: co-locate the wrong pair and you pay communication tax forever; let oneGPU host all the hot experts and it becomes a straggler for everyone else.
Existing placement strategies are either offline(compute a fixed layout from historical traces — fast, but stale when workloadsshift) or online reactive (rebalance based on the last batch — always astep behind the actual demand). Both treat placement as something to catch upto. DIRECTOR flips it: predict what the next batch will route to,and place experts before that batch arrives.
11–55% lower end-to-end latency across Mixtral, DeepSeekMoE, DeepSeek-V2-Lite, and Qwen3, on bothRTX 4090 and H200 clusters. The gain grows with cluster size — from 11% at 4GPUs to 48% at 32 GPUs — because larger systems are more sensitive to a singlemis-placed expert. And it beats Simulated Annealing by 14–26 percentage points,showing the LP-relaxation path finds genuinely better placements, not justfaster ones.