.png)
Simplicity is the ultimate sophistication --Leonardo da Vinci
A world model gives a robot an internal simulator. Show it the current view and the action you want to take, and it generates a realistic video of what would happen next — letting the robot "imagine" outcomes before moving a single motor in the real world.
Our model, IRASim, makes every generated frame line up precisely with the action behind it. The result is video that captures the subtle stuff robots actually struggle with — a bowl slipping from the gripper, a block being nudged, a drawer sliding shut — in high resolution and over long horizons.
Why it matters:
More details can be found at: https://gen-irasim.github.io/
See the demos below 👇
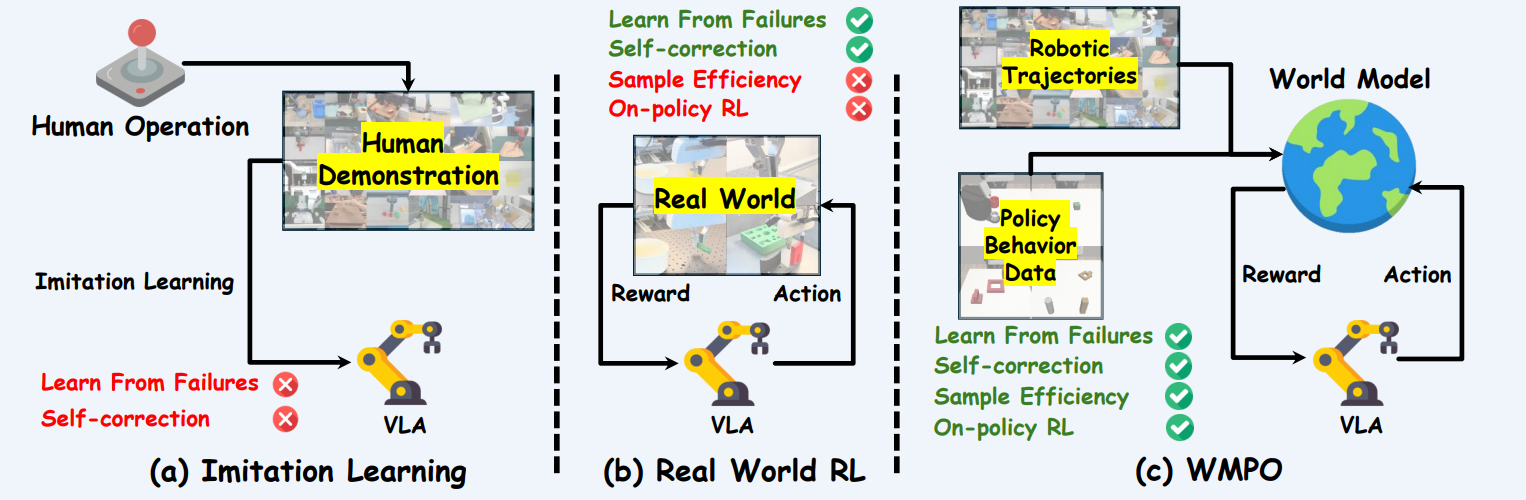
If a world model can faithfully imagine what happens next, then a robot can do more than just watch — it can practice inside its own head.
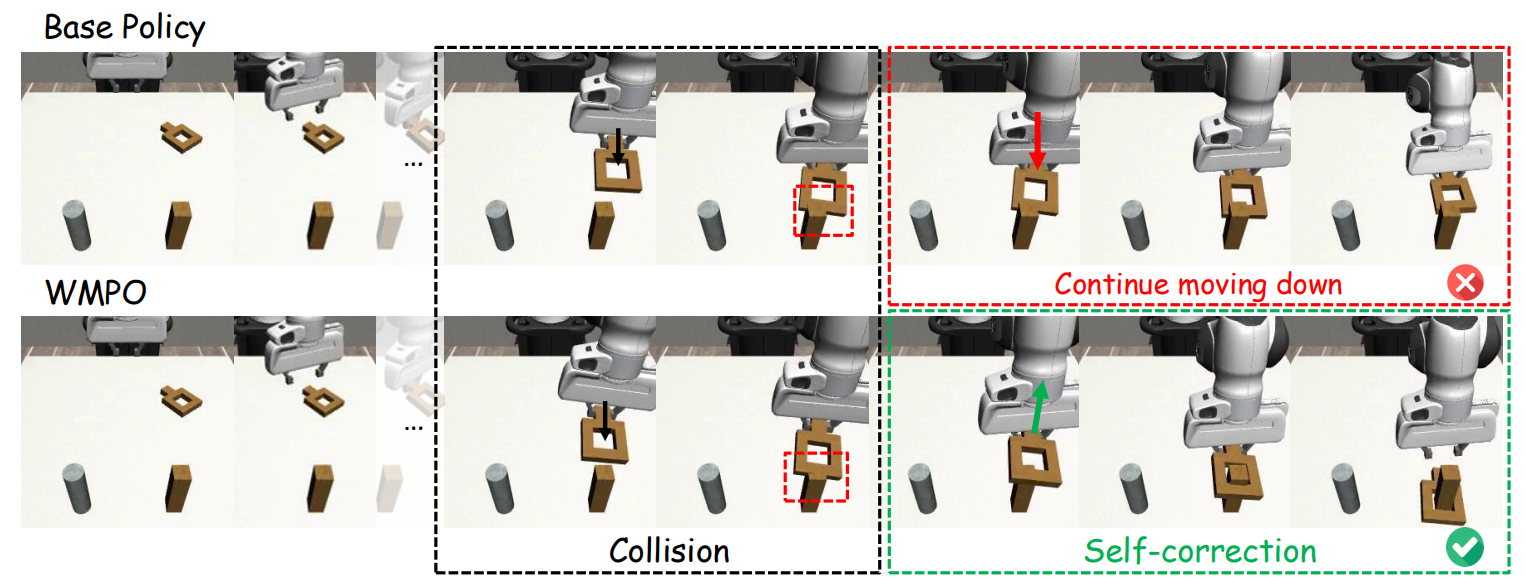
That's the idea behind our follow-up work, WMPO (World-Model-based Policy Optimization). Instead of sending the robot back into the lab to collect thousands of new trials, we let it train entirely inside the imagined world. The robot tries, fails, tries again — all in pixels generated by our world model — and gradually becomes better at the real task.
What this unlocks:
More details can be found at: https://wm-po.github.io/
What if the robot didn't need a separate world model running alongside it — what if imagining the future became part of how it thinks?
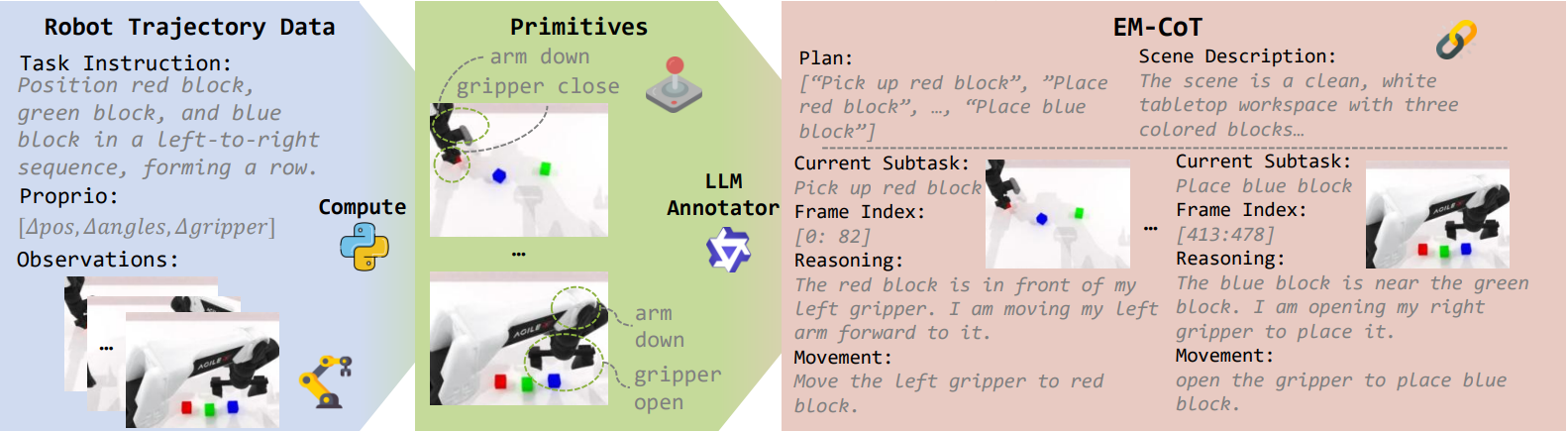
That's the leap behind HALO. Given a goal like "arrange the blocks in red-green-blue order," it works the way people do:
Why it matters:
Our code is released at: https://github.com/qshou-coder/HALO
See HALO in action below 👇
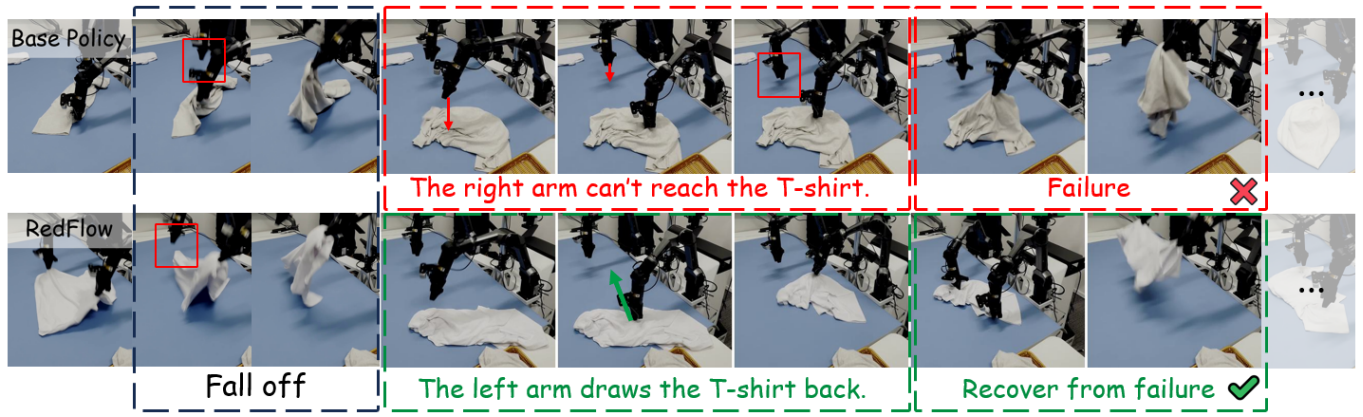
Robots fail a lot. Most methods treat a failed attempt as one big "bad example" — but inside a failed try, most of the actions were fine. The mistake is usually one specific moment that sent everything off course.
RedFlow zooms in on those moments. For each failure, it pinpoints the exact step that went wrong, finds a similar moment from a successful attempt, and uses it as a concrete example of what should have happened. Instead of just "don't do that," it shows the robot "do this instead."
Why it matters:
See RedFlow recover from its own mistakes below 👇
Research is one thing. Getting it to actually run on a robot in front of you — synchronized cameras, smooth motion, safe execution — is another.
RTC-Anything is the deployment framework we built to close that gap. It takes any of the policies above and runs them on real Agilex robots, with real-time action chunking that keeps motion fluid instead of jerky. The framework is model-agnostic (swap in your own policy backend) and task-agnostic (clothes folding, sweeping, cleaning — all share the same runtime).
What's included:
You can find RTC-Anything at: https://github.com/PEILAB-PhysAI/RTC-Anything
Everything is open-source — grab the code, plug in your robot, and start deploying 👇
